Vapor Performance - Fluent Optimisations
In this tutorial, you’ll learn how to:
- Optimise your database connections for Vapor.
- Make efficient database calls with Fluent.
Note: You’ll need the following for this project:
> Xcode 13.1 and Swift 5.5 (or newer versions).
> Docker. If you don’t have Docker yet, visit Docker install for Mac.
Getting Started
Download the starter project by clicking here. Then, navigate to the starter folder. Open the Vapor app in Xcode by double-clicking Package.swift. While the dependencies resolve, check the existing project in /Sources/App/:
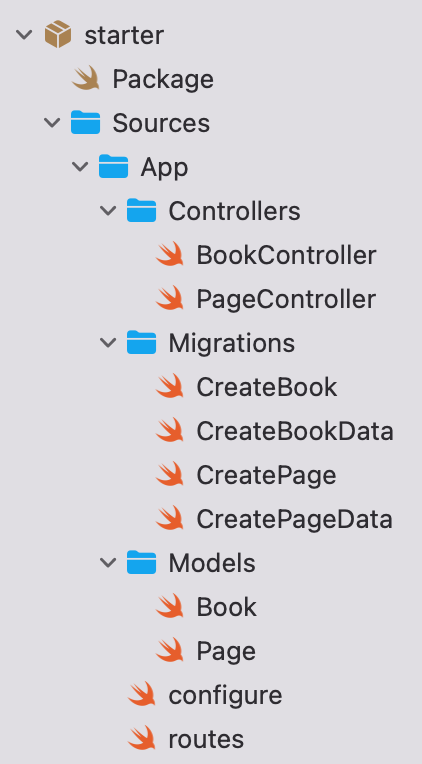
Here you’ll see:
Controllers: TheBookController.swiftandPageController.swiftwhich contain the functions that handle requests and return responses.Models: Has theBookCrawlermodel files.Migrations: Includes theBookCrawlertable definitions and seed data.configure.swift: Contains the database connection details.
Configuring Your Local MySQL Database Using Docker
Next, configure your MySQL container. Open your terminal and paste the following command:
docker run --name=mysql-server -e MYSQL_DATABASE=vapor_database -e MYSQL_USER=vapor_username -e MYSQL_PASSWORD=vapor_password -e MYSQL_ROOT_PASSWORD=vapor_password -p 3307:3306 -d mysql
This command:
- Runs a new container named
mysql-server. - Pulls the
mysqlimage if it doesn’t already exist on your machine. - Specifies the database name,
vapor_database, username,vapor_username, and password,vapor_password, through environment variables. - Instructs the container to listen on port
:3307and exposes the port to your local machine.
Note: If you already have a MySQL database configured on port 3307, change the port before you run the command, e.g. -p 3308:3306. Remember to update the database configuration in
configure.swiftif you make any changes to the port, --name, MYSQLDATABASE or MYSQLUSER.
Connecting to your Database
The steps to connect to MySQL through your Vapor application are already implemented in configure.swift. So, build and run.
Open the configure.swift file to find the database connection details. The import FluentMySQLDriver imports the driver used to interact with the database and provides it with the database address and authentication information.
When connecting to the database over a network, you should secure the connection using TLS with appropriate settings:
tls.certificateVerification = .fullVerification
tls.minimumTLSVersion = .tlsv12
tls.trustRoots = .file("/path/to/CA_certificate_file")
As the database is present locally, you see TLS skipped with tls.certificateVerification = .none
Connection Pools
Creating a database connection takes time and resources for connecting, encrypting and authenticating. Making a new connection for every request to the database would be slow and inefficient. To prevent this, used connections remain open for re-use by any future requests.
The connection protocol used by MySQL is half-duplex so the connection only sends or receives data at any given time. Connections aren’t shared between EventLoops so you should have at least one connection per EventLoop. So you keep a pool of connections available to each EventLoop in the application by specifying the most number of connections you would want available in the configuration as below:
app.databases.use(.mysql(configuration: dbConfig, maxConnectionsPerEventLoop: 2), as: .mysql)
The default value for maxConnectionsPerEventLoop is one if not specified. So, new connections do not get closed unless the number of open connections from the EventLoop exceed the maxConnectionsPerEventLoop count, two in this case.
Note: Keeping a database connection open also consumes resources so there are a finite amount of connections that the database allows you to keep open. Ensure you don’t cross that limit by calculating the total connections made from your application as follows:
Application connections = Number of CPU cores * maxConnectionsPerEventLoop
By default, you have oneEventLoopper processor core.Assuming you have a machine with 4 cores and 2maxConnectionsPerEventLoopyou would end up with a maximum of 8 open connections.
Keeping an adequate amount of connections available to an EventLoop should improve the performance of its parallel queries and concurrent database requests.
Modelling Refresher
Note: This section is optional, because it forms the basis of Fluent which you may already know . If you’d like to dive right into optimisations, feel free to skip ahead to the "Making Database Calls" section.
Storing and retrieving from database tables requires encoding and decoding Swift data by conforming Models to the Content protocol.
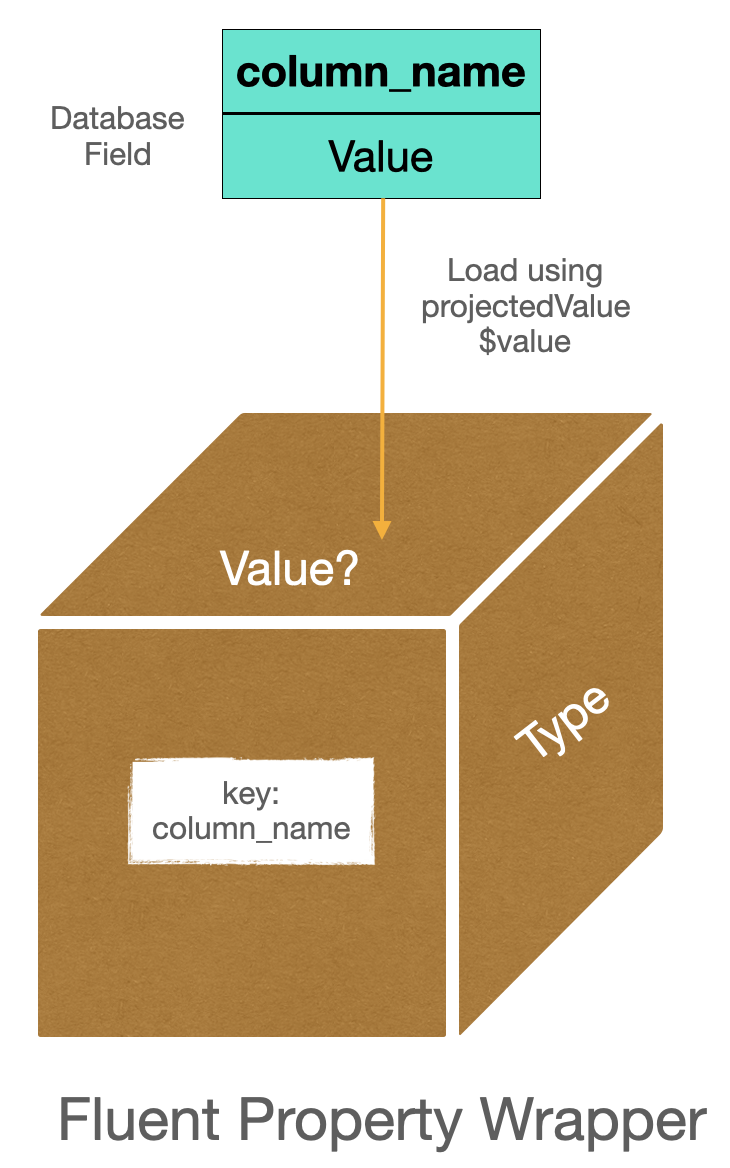
Property wrappers encapsulate properties with extra data and logic that is accessible without having to write it explicitly each time:
- Accessing the
propertyWrapperTypereturns thewrappedValuewithout the need to mentionpropertyWrapperType.wrappedValue. - Using
$propertyWrapperTypereturns theprojectedValuefunctionality if it is present.
Fluent uses property wrappers to provide the metadata required to map properties onto their database representations and to ensure the value is not used before initialisation.
- The schema defined in the
Modelclass provides the table mapping. - The Property Wrappers provide the column mapping.
ID Property Wrapper
ids are the identifiers that are generally primary keys of their database tables and are thus unique. Properties demarcated with @ID correspond to the id of the model and generate the id value as a UUID for you before saving the data in the database table. This comes with the added advantage of not relying on your database to generate the ID value which is turn saves you from having to make an additional query to get back the DB generated ID.
It is an optional property as the ID generation may not have taken place before saving it in the database. To get the ID value use requireID on the property. It will throw an error in case it’s nil.
When you need to map the id field to an existing database table, use a custom column name or have it generated by the database use the custom key like:
@ID(custom: "page_id", generatedBy: .database)
var id: Int?
Ensure the migration is in place too
.field("page_id", .int, .identifier(auto: true))
Serially generated Ids are not desirable as they are predictable and expose certain data points unintentionally. It also becomes an issue if you want to shard your database.
Making Database Calls
Note: If you skipped ahead from earlier, you can continue with the
BookCrawlerwithout having missed anything.
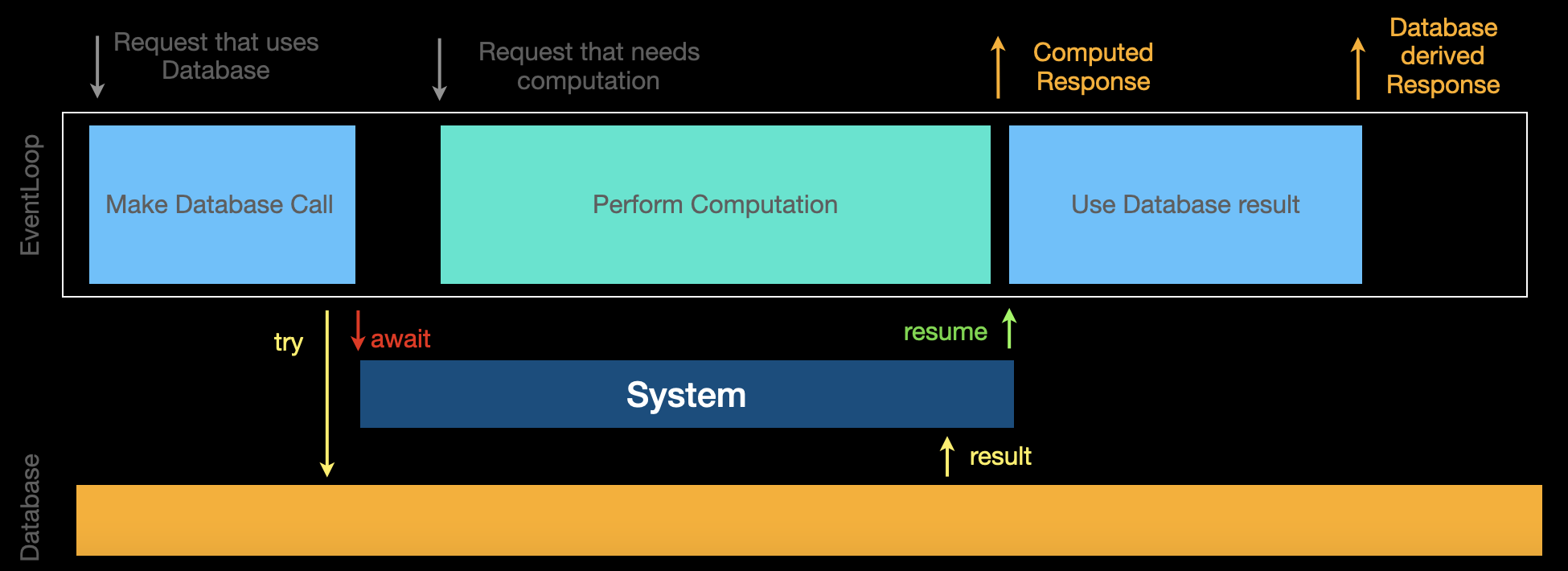
The database used in a production environment may not be on the same machine as your application. Hence each round trip to the database would have some added latency and consume bandwidth.
Hence you should look to: - Keep the database calls to a minimum. - Reduce data returned in the result to consume lesser bandwidth.
There’s also the possibility of an error occurring when performing a database operation due to an issue with the connection, authentication or data integrity. Hence every database call can throw.
You don’t want to block the thread while waiting for response so all database requests are async by default so as to let other work continue.
So you prefix every database call with try await and consider it to be a request, hoping the response arrives with the result.
Handling Database Errors
The BookCrawler app allows users to create books using its API endpoint. In the BookController file you have the create function which handles any HTTP request to the books path as:
func create(req: Request) async throws -> Book {
// 1
let book = try req.content.decode(Book.self)
// 2
try await book.create(on: req.db)
return book
}
This function:
- Decodes the JSON body in the HTTP request payload into a
Bookobject. - Creates a new entry in the
bookstable for thebook.
This creates the book with the given title unless a Book with that title already exists. This is due to the unique database constraint applied on the title in the CreateBook migration .unique(on: "title")
To create a new book, open Terminal and paste in the request below:
curl --location --request POST 'http://localhost:8080/books/' \
--header 'Content-Type: application/json' \
--data-raw '{
"words": 1500,
"title": "The man who knew too much",
"price": 99.00,
"type": "fiction",
"form": "shortStory"
}'
This will return the request with the payload containing the created book details in JSON including the auto-generated UUID though you didn't provide any id as Fluent updates the underlying model implicitly when the query succeeds (as can be seen in the line try self.output(from: SavedInput(self.collectInput())) from the _create func in Model -> Model+CRUD extension) :

Send the same request again and you receive a 500 Internal Server Error error in the HTTP Response 
This is due to the error from the database as it’s constraint check fails which bubbles up to the ErrorMiddleware which returns the response with the Abort error and reason.
To return an apt error or a clearer reason you should catch the expected error and throw a more appropriate error with better reasoning. To handle the constraint violation exception replace your existing implementation of create with the following:
func create(req: Request) async throws -> Book {
let book = try req.content.decode(Book.self)
do {
try await book.create(on: req.db)
} catch let error as DatabaseError where error.isConstraintFailure {
throw Abort(.forbidden, reason: "A book with that title already exists")
}
return book
}
Here you’ve enclosed the create call within a do-catch statement. In case of a constraint violation it gets caught and rethrown with a more descriptive 403 Forbidden HTTP error response with the reason mentioned.
Repeat the same request now and you receive a response as below:
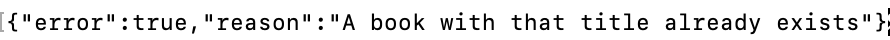
Much Better! If there is some uncaught error thrown it will still return as before.
Optimising Database Calls
There can be several ways to do the same thing. Engineering is about picking the right trade-offs. Let’s contrast and compare some database querying approaches for the BookCrawler and see their prose and cons. You'll be focussing on reducing:
- Network calls
- Memory usage
This should enable your application to have relatively faster responses. Every time you process faster, you not only provide a better user experience but also consume fewer resources as you use them for a lesser time and allow for more operations with the same amount of resources at your disposal.
Note: Profile your app and keep an eye on metrics.
To view the SQL queries generated along with the number of queries generated while developing, set the log level to debug in theconfigure.swiftfile by usingapp.logger.logLevel = .debug.
Also check
- Network usage in Xcode's Debug navigator -> click Network.
- Memory usage in Xcode's Debug navigator -> click Memory.
to see the usage difference when trying out different queries.
Automating Query Generation
The BookCrawler app allows users to search for text content in the book pages to let them know if it has what they are looking for.
To search for Pages containing any content that matches a given search term, open Terminal and paste the request below:
curl --location --request GET 'http://localhost:8080/pages/search?term=ips' \
--header 'Content-Type: application/json'
It will return an array of matching Pages as below: 
Lets inspect the search function in the PageController file that's responsible for finding pages containing content with the requested search term.
import FluentSQL
func search(req: Request) async throws -> [Page] {
// 1
guard let searchTerm = req.query[String.self, at: "term"] else {
throw Abort(.badRequest, reason: "invalid search query")
}
//2
guard let sqldb = req.db as? SQLDatabase else {
throw Abort(.internalServerError)
}
// 3
let query = sqldb.raw("SELECT * FROM pages where content LIKE '%\(searchTerm)%'")
// 4
let matchingPages = try await query.all(decoding: Page.self).get()
// 5
return matchingPages
}
Here you:
- Validate the
termrequest query parameter. - Ensure the database is a SQL database that will support
rawqueries. - Define the SQL Query that will pattern match the
contentof all records in thepagestable. - Request the database to execute the query and decode the retrieved result using the
Pagemodel. - Return the matching pages as an array of Pages.
It’s better to avoid raw SQL whenever possible as it:
- Is not type-checked and is error prone due to typos in the field and table names.
- Requires every raw SQL query to be manually updated if there's a change in the database or else it will throw an error at runtime.
- Is susceptible to SQL injection attacks.
Parameterising Queries
There may be times when you want to use raw SQL to leverage some database specific functionality that Fluent doesn’t support. In such cases you can use a parameterized query as below:
// 1
let table = "pages"
// 2
let searchExpression = "%\(searchTerm)%"
// 3
let query = sqldb.raw("SELECT * FROM \(raw: table) WHERE content LIKE \(bind: searchExpression)")
// 4
let matchingPages = try await query.all(decoding: Page.self).get()
Here's what this does:
- Defines the
pagestable as a string parameter. - Defines the search expression which will be the bind parameter for the parameterised query.
- Sets up a parameterised query with the search expression as its bind parameter.
- Request the database to execute the parameterised query and decode the retrieved result using the
Pagemodel.
This should help maintain your code better and prevent SQL injection attacks.
Building Queries
Use Fluent’s QueryBuilder to generate the SQL from the Swift Model mappings.
Replace your existing implementation of search with the following function:
func search(req: Request) async throws -> [Page] {
// 1
guard let searchTerm = req.query[String.self, at: "term"] else {
throw Abort(.badRequest, reason: "invalid search query")
}
let matchingPages =
// 2
try await Page.query(on: req.db)
// 3
.filter(\.$content ~~ searchTerm)
// 4
.all()
return matchingPages
}
Here you:
- Validate the search query parameter.
- Use the
QueryBuilderthat generates a more efficient version of the raw SQL query above, specifying all the required column names, and decodes the result into Page objects. - Filter by content to only keep the pages which contain the searchTerm.
filteruses theprojectedValuefrom the property key path to get the column name for the content property. Combined with the~~operator it generates a where condition that will match any content substring in the table column with thesearchTerm. - Return all the rows generated from the query.
Then build and run. Repeat the earlier request and you should receive the same response using the QueryBuilder.
There are other operators that you can use for more specific pattern matching like if you wanted to restrict to matching the prefix (=~), suffix (~=) and their inverse conditions (prefixed with !).
This should help with using the QueryBuilder wherever possible. But that's not all. The QueryBuilder offers a lot more which you'll look into in the next section.
Reducing Memory Usage
The BookCrawler app also likes to boast about its growing collection of books by showing the total number of books in its library whenever possible. So the count API is a frequently used one.
To get a count of all books in your database you can send a request as:
curl --location --request GET 'http://localhost:8080/books/count' \
--header 'Content-Type: application/json'
This will return the count as: > 13
The count function in the BookController handles this request which gives the number of books in the database.
func count(req: Request) async throws -> Int {
try await Book.query(on: req.db).all().count
}
This function loads the entire list of books from the database into the application memory and returns the count of the array. This should send some alarm bells ringing.
Aggregating
Ideally, you should perform data intensive operations as close to the data as possible and that's applicable here as well. You do this here by using a database aggregate function which will perform the calculation in the database and return only the final number as the result thereby reducing the memory and network usage.
Replace the count function with:
func count(req: Request) async throws -> Int {
try await Book.query(on: req.db).count()
}
This will generate a database query to calculate the count of rows in the books table and only returns the number of books in the result.
Now stop, build and run again. Send the earlier request again and you should receive the same response as before in the ink of an eye. Though seems to be the same on the outset it consumes a lot less memory and network resources.
There are other aggregates for performing calculation on the database are sum, average, min and max which should help you perform calculations in the database whenever you need them. For more complex data intensive operations you should consider using stored procedures.
Minimising Network Usage
Sales and discounts come around every so often and the BookCrawler app allows you to conveniently apply a flat discount across certain types of books with just an API call. The book/discount endpoint applies a flat discount price on all fictional books and you can invoke it by sending a request as:
curl --location --request PUT 'http://localhost:8080/books/discount?price=9' \
--header 'Content-Type: application/json'
Which will return a 200 success HTTP response once the discount price gets applied.
The applyDiscount function in the BookController file handles this request to set the discountPrice of all fiction books to the discountedPrice if its price is greater than the discountedPrice.
func applyDiscount(req: Request) async throws -> HTTPStatus {
// 1
guard let discountedPrice = req.query[Decimal.self, at: "price"], discountedPrice > 0 else {
throw Abort(.badRequest, reason: "Invalid discount price")
}
let booksToBeDiscounted =
// 2
try await Book.query(on: req.db)
.filter(\.$type == .fiction)
.filter(\.$price > discountedPrice)
.all()
// 3
for book in booksToBeDiscounted {
book.discountPrice = discountedPrice
try await book.update(on: req.db)
}
// 4
return .ok
}
Here you:
- Validate the
discountedPriceprovided in the request's query parameter. - Fetch all
.fictionbooks with price greater than thediscountedPricefrom the database into memory using one query. - Update the
discountPriceof the fetched books to thediscountedPriceand save the updated value back to the database for each book which uses as many update queries as there are books. Definitely a red flag! - Return a
200 OKHTTP Response.
As you can tell, this is quite inefficient in terms of memory usage and database calls. Lets improve this using the QueryBuilder’s set and update method.
You can replace the method with:
func applyDiscount(req: Request) async throws -> HTTPStatus {
// 1
guard let discountedPrice = req.query[Decimal.self, at: "price"], discountedPrice > 0 else {
throw Abort(.badRequest, reason: "Invalid discount price")
}
// 2
try await Book.query(on: req.db)
.set(\.$discountPrice, to: discountedPrice)
.filter(\.$type == .fiction)
.filter(\.$price > discountedPrice)
.update()
// 3
return .ok
}
The function now:
- Validates the
discountedPriceprovided in the request's query parameter. - Performs the filter and update operations directly in the database using
set()andupdate()in theQueryBuilderwhich generates a single query with the required information to execute in the database. - Returns a
200 OKHTTP Response.
Now stop, build and run again. Repeat the earlier request and you still receive the same response as before. It's all the same but very different under the cover.
Joining Data
What good is a book without its pages? You'll be lost for words. Each Book has several Pages so they have a Parent-Child or One-to-Many relationship. The relationship is present in the Book model as:
@Children(for: \Page.$book)
var pages: [Page]
As well as the Page model:
@Parent(key: "bookId")
var book: Book
This lets you access Books from their associated Pages and vice-versa.
While browsing for books under a certain price point, the BookCrawler app includes the sample pages of those books to give users a taste of what they can expect. To get the books with their sample pages open Terminal and send the request below:
curl --location --request GET 'http://localhost:8080/books/samples?price=200' \
--header 'Content-Type: application/json'
Which will return JSON data like:
The getSamplePages function returns books with sample child pages, using the BookWithPages DTO.
> Note: A Domain Transfer Object (DTO) serves as a good medium for returning results in a specific format.
func getSamplePages(_ req: Request) async throws -> [BookWithPages] {
guard let selectedPrice = req.query[Decimal.self, at: "price"] else {
throw Abort(.badRequest, reason: "Invalid price")
}
var booksWithPages: [BookWithPages] = []
let books =
// 1
try await Book.query(on: req.db)
.filter(\.$price < selectedPrice)
.all()
for book in books {
// 2
let pages = try await book.$pages.get(on: req.db)
// 3
let samplePages = pages.filter(\.isSample)
// 4
if !samplePages.isEmpty {
booksWithPages.append(BookWithPages(title: book.title, pages: samplePages))
}
}
return booksWithPages
}
Here the code:
- Fetches all
booksunder theselectedPricewithout anypages. - Loads all the
pagesfor thatbookinto memory, lazily, as and when required. Thepagesfor thatbookare not loaded before this point. Trying to access thesebookpageswithout fetching them from the database will result in an error as the underlyingoptionalvalue of the property wrapper isn't initialized. Don't judge a book by its wrapper! - Keeps the sample pages.
- Excludes books that have no sample pages.
This would generate one database query for the Books, and then N additional select queries in each iteration of the for loop to get the pages of each book. This is the N+1 Selects issue. The larger the data set, the more it becomes. Time to book it. You're not letting this one get away.
Eager Loading
You can avoid these additional N round trips to the database by eager loading the pages of each book along with the book by adding with() children at the time of fetching the data. To do this replace the getSamplePages with the code below:
func getSamplePages(_ req: Request) async throws -> [BookWithPages] {
guard let selectedPrice = req.query[Decimal.self, at: "price"] else {
throw Abort(.badRequest, reason: "Invalid price")
}
var booksWithPages: [BookWithPages] = []
let books = try await Book.query(on: req.db)
// 1
.filter(\.$price < selectedPrice)
// 2
.with(\.$pages)
.all()
for book in books {
// 3
let samplePages = book.pages.filter(\.isSample)
// 4
if !samplePages.isEmpty {
booksWithPages.append(BookWithPages(title: book.title, pages: samplePages))
}
}
return booksWithPages
}
Here your new code:
- Gets all
books under theselectedPrice. - Loads all the
pagechild objects for each bookeagerly using one additional queryfor all the books due to thewith()function.
Note: You can’t add
.filter(\Book.$pages.$isSample == true)to filter the child pages directly aswith()creates a separate query after the first one to get the additional results. Neither does it perform a join nor does it perform any of the additional filter operations.
- Only keeps the sample pages.
- Excludes books that have no sample pages
Now stop, build and run again. Use the earlier request again and you should receive the same response by eager loading. This is far more efficient and you should use the same number of queries even as your data set grows.
Joins
You can actually do one better and use a join() to get all the data in a single query. Use the function below in your code:
func getSamplePages(_ req: Request) async throws -> [BookWithPages] {
guard let selectedPrice = req.query[Decimal.self, at: "price"] else {
throw Abort(.badRequest, reason: "Invalid price")
}
var booksWithPages: [BookWithPages] = []
let pages =
// 1
try await Page.query(on: req.db)
.filter(\.$isSample == true )
// 2
.join(Book.self, on: \Page.$book.$id == \Book.$id)
// 3
.filter(Book.self, \.$price < selectedPrice)
.all()
// 4
let groupByBook = try Dictionary(grouping: pages) { page -> String in
// 5
let book = try page.joined(Book.self)
return book.title
}
// 6
for book in groupByBook {
booksWithPages.append(BookWithPages(title: book.key, pages: book.value))
}
return booksWithPages
}
With the function above you are:
- Getting all sample pages from the
Pagetable. - Using a
join()betweenPageandBookon the book'sid. This generates an inner join between the database tables which selects pages that have matchingBookids in both tables.
Note: Notice the use of projected values of the fields for all the query filters including the child models like
Page.$book.$idto obtain the column names for the join condition.
- Filtering on the joined
Bookfor books priced under theselectedPrice. - Grouping the pages based on the book into a dictionary.
- Decoding the
Page’s parentBookfrom memory using joined as it’s not directly accessible using thebookproperty` before this. - Adding books with their sample pages from the grouped dictionary into the DTO.
Now stop, build and run again. Send the initial request again and you should receive the same response as you did for the previously. You've outdone yourself and got your query count down to one! The response may be the same but there's more to it than meets the eye. Don't judge a book by its cover.
Where to Go From Here?
In this article, you saw some ways to use your database effectively with Fluent and how you can optimise your usage.
Want more books about Fluent? Check out Server-Side Swift with Vapor. The official Vapor documentation should help you too.
Craving some food for plot? Here's some if you're looking for a challenge beyond this tutorial:
- Sort and restrict the amount of result data using fields.
- Implement a sibling relationship with additional properties on the pivot.
- Create a stored procedure and call it from your Vapor code.
Book your questions or comments at [email protected] or tweet @jawadhf. If you come across any inaccuracies, errors or typos that require correction, let me know.
Join the Vapor community at the Vapor Discord server.